












What Are the Best Search APIs to Use With Large Language Models?
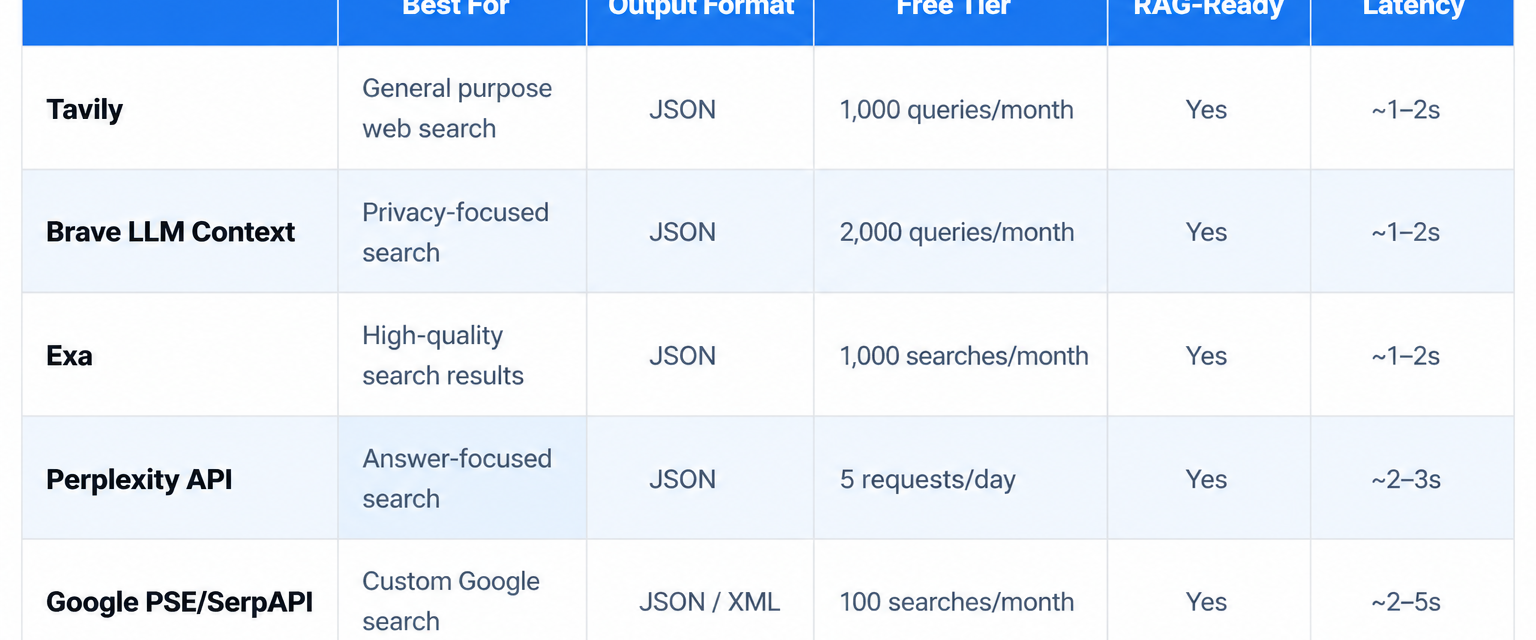
The top LLM search APIs in 2026 are Tavily, Brave LLM Context API, Exa, Perplexity API, and Google Programmable Search Engine (PSE), each optimized for different aspects of AI agent and RAG pipeline performance.
These providers are not interchangeable. Tavily is purpose-built for RAG pipelines, aggregating up to 20 sites in a single API call using proprietary AI ranking, according to a detailed April 2025 comparison on Zenn. Brave LLM Context API delivers pre-chunked, relevance-ranked Markdown output designed for grounding. Exa specializes in semantic and neural search, returning full page content rather than snippets. Perplexity API handles NLU-heavy queries well but returns summarized answers rather than raw retrievable context. Google PSE and SerpAPI provide the broadest web coverage but require multi-step post-processing before content is LLM-ready.
As Matt Collins documents in his guide to web search APIs for LLMs, the field has shifted decisively from raw SERP data toward context-ready content that AI agents can consume directly. The 2026 provider landscape overview from Firecrawl confirms this trend, with LLM-native APIs now outnumbering traditional SERP wrappers in active developer adoption.
Top LLM Search APIs at a Glance
How Does Real-Time Web Search Improve LLM Responses?
Real-time web search APIs solve LLMs' most fundamental limitation: static training data. They ground responses in live, up-to-date information retrieved at inference time, not at training time.
Every LLM has a knowledge cutoff. Ask GPT-4o about a product launched three months ago or a regulatory change from last quarter, and you get either a hallucinated answer or an admission of ignorance. Search APIs fix this by injecting fresh context into the prompt or RAG pipeline before generation runs. According to Built In's analysis of search engines for AI LLMs, search APIs enable LLMs to avoid static, outdated datasets by delivering answers grounded in live web data at the moment of inference. For time-sensitive B2B queries covering pricing, compliance, or competitive positioning, the difference between a training-data answer and a live-web answer is the difference between useful and wrong.
The ML6 blog's comparison of how LLMs access real-time data maps three distinct approaches across ChatGPT, Gemini, and Perplexity: native browser tools, retrieval plugins, and API-level search injection. For developers building production pipelines, API-level injection gives the most control over what context reaches the model.
Freshness filtering makes retrieval precise rather than just current. The Brave Search API's LLM Context endpoint exposes a freshness parameter that constrains results by publication date, ensuring a query about "Q1 2026 SaaS pricing trends" returns content from that window rather than evergreen articles from 2022. The freeCodeCamp walkthrough on adding real-time search to an LLM using Tavily provides a concrete implementation of this pattern for developers starting from scratch.
What Features Should You Look for in an LLM Search API?
The most important features in an LLM search API are pre-extracted content output, relevance ranking optimized for AI, freshness filtering, single-call aggregation, and native support for RAG and tool-calling frameworks.
Pre-extracted or chunked output. The API should return clean text or Markdown, not raw HTML. Raw HTML forces your pipeline to run a parser and chunker before the LLM sees anything, burning tokens on boilerplate, navigation menus, and cookie banners. As WebSearchAPI.ai explains in its foundational guide, the core value of an AI-optimized search API is that it handles content extraction server-side, delivering only the signal your model needs.
AI-optimized relevance ranking. PageRank and keyword frequency are designed for human browsers. LLM search APIs use semantic relevance scoring to surface content that answers the query. The Brave LLM Context API documentation describes relevance-scored chunks and structured data extraction as core outputs, not optional features.
Freshness filters. Date-range controls let you constrain results to a specific publication window. Available natively in Brave LLM Context API and Tavily.
Single-call aggregation. Tavily scrapes, filters, and extracts content from up to 20 sites in one API call, according to the Zenn comparison of search APIs for LLMs, collapsing what would otherwise be a five-step pipeline into a single network request.
Rate limits and scalability. One tested API supports 20 calls per second, according to GoPubby's analysis of enhancing LLMs with search APIs. Confirm rate limits before committing to a provider in production.
Context window compatibility. Brave recommends LLMs with a 32k context window to handle the data volume its LLM Context API returns per query, as noted in the GoPubby analysis. Pairing a high-output search API with a small-context model wastes the retrieval advantage.
Framework integrations. Native support for LangChain, LlamaIndex, and liteLLM reduces integration time from days to hours.
Privacy model. Every query sent to an external search API leaves your infrastructure. For pipelines handling sensitive B2B data, evaluate whether the provider logs queries, retains data, or offers a private deployment option.
How Do LLM Search APIs Enhance RAG Workflows?
LLM search APIs replace multi-step scrape-parse-chunk pipelines with a single API call that returns relevance-ranked, LLM-ready content, collapsing RAG retrieval from seven steps to one.
Before LLM search APIs: Query → SERP API → scraper → HTML parser → chunker → embedder → vector store → retriever → LLM
That is seven steps, each introducing latency, failure points, and infrastructure cost. The scraper breaks on JavaScript-heavy pages. The parser strips useful structure. The chunker makes arbitrary cuts. The embedder adds compute cost. The vector store needs maintenance.
After LLM search APIs: Query → LLM Search API (single call) → ranked excerpts → LLM
Tavily performs searching, scraping, filtering, and extraction in a single API call, per the Zenn LLM search API comparison. The Parallel Search API quickstart documentation describes replacing multiple sequential searches with single natural language calls that return LLM-ready excerpts directly, optimized for complex or broad objectives.
For RAG grounding specifically, the Brave LLM Context API delivers relevance-ranked chunks in Markdown format, ready to paste into a system prompt or retrieval context block without additional processing.
RAG-specific features by provider:
- Tavily: single-call search + scrape + filter + extract; native LangChain tool
- Brave LLM Context API: relevance-scored Markdown chunks; freshness filtering; 32k context window optimization
- Exa: full page content retrieval; strong semantic matching for research-heavy queries
- Parallel Search API: natural language objective input; designed for complex multi-source queries
How Do I Integrate a Search API With an LLM Pipeline or AI Agent in Python?
Integrating a search API with an LLM pipeline in Python takes fewer than 20 lines of code using LangChain's tool-calling interface or a direct API wrapper, with Tavily and Brave offering the most plug-and-play developer experience.
1. Direct API call using Python requests or a provider SDK. Set your API key, POST a query, parse the JSON response, and inject the returned text into your prompt. No framework dependency. Works with any LLM. Best for prototyping or lightweight pipelines where you control the full prompt construction.
2. LangChain tool integration. LangChain provides official wrappers for Tavily (`TavilySearchResults`) and community wrappers for Brave and SerpAPI. As Matt Collins documents in his LLM search API guide, tool-calling in LangChain lets AI agents decide when to invoke search rather than running it on every query, reducing unnecessary API calls and latency. A minimal LangChain agent with Tavily:
```python from langchain_community.tools.tavily_search import TavilySearchResults tool = TavilySearchResults(max_results=5) agent = initialize_agent(tools=[tool], llm=llm, agent="zero-shot-react-description") agent.run("What are the latest LLM search API benchmarks for 2026?") ```
The freeCodeCamp guide to adding real-time web search with Tavily walks through this pattern step by step, including environment setup and error handling.
3. liteLLM web search wrapper. For teams using multiple LLM providers, liteLLM's web search integration provides a provider-agnostic layer that routes search calls through your preferred backend without rewriting integration code when you switch models.
Each search API call executes in approximately one second, according to GoPubby's LLM search API analysis. In multi-step agent workflows where the agent calls search three or four times per task, that latency accumulates. Batch queries where possible or cache results for repeated lookups.
For open-source integration examples, the LangChain and LlamaIndex GitHub repositories maintain up-to-date tool wrappers for Tavily, Brave, Exa, and SerpAPI. The OpenAI developer community thread on implementing web search with LLMs surfaces real-world integration questions and workarounds that documentation does not always cover.
Are There Free or Open-Source LLM Search APIs?
Yes. Several LLM search APIs offer free tiers or open-source integrations, including Tavily, Google Programmable Search Engine, and Brave Search API, making it feasible to prototype AI agents at zero cost.
Tavily's free tier covers approximately 1,000 searches per month, includes the full single-call aggregation pipeline, and connects directly to LangChain with no additional configuration. Google PSE provides 100 free queries per day via Google Cloud with broad web coverage, though it returns raw SERP data requiring extra parsing before it is LLM-ready, as noted in the Zenn API comparison. Brave Search API has a free tier with access to its LLM Context endpoint. Exa offers trial credits for semantic search evaluation. SerpAPI provides a 100-search trial but requires a paid plan for ongoing use.
On cost: search APIs charge per query, while internal vector-store RAG charges for embedding compute and storage. For low-to-medium query volumes, search APIs are cheaper than maintaining a full vector infrastructure, according to Built In's analysis of AI search engines for LLMs. The break-even point depends on query volume and whether your use case requires proprietary internal documents (where vector RAG is irreplaceable) or public web content (where search APIs win on cost and freshness).
A broader survey of eight web search APIs for AI agent builders, published by Fardeen on Medium, covers additional providers with niche strengths in news retrieval and academic content. For practitioner opinions on which free options hold up under real workloads, the Reddit r/n8n thread on the best search API for LLM pipelines is worth reading before committing to a provider.
Open-source framework support (LangChain, LlamaIndex) reduces vendor lock-in regardless of which API you choose. Switching from Tavily to Brave or Exa requires changing one import and one initialization line, not rewriting your agent architecture.
Free Tier Quick-Reference
Traditional SERP APIs vs. LLM-Optimized Search APIs: What's the Difference?

Traditional SERP APIs return raw keyword-matched search results designed for human browsers. LLM-optimized search APIs return pre-processed, relevance-ranked, context-ready content designed for AI consumption. This is a fundamental architectural difference that affects latency, token efficiency, and answer quality.
SerpAPI and Google PSE return titles, URLs, and snippets in JSON. Your pipeline then has to scrape the pages, parse the HTML, strip the noise, chunk the text, and feed it to the LLM. LLM-optimized APIs (Tavily, Brave LLM Context, Exa) do that work server-side. As Matt Collins writes in his web search API guide, SERP APIs hand you raw ingredients while LLM APIs hand you a prepared meal.
Three dimensions separate the two categories:
Ranking signal. SERP APIs rank by keyword relevance and PageRank-style signals calibrated for human click behavior. LLM-optimized APIs rank by semantic relevance to the query intent. The Zenn comparison contrasts Tavily's AI-optimized ranking directly against Google's keyword-focused approach.
Output format. Raw SERP JSON vs. pre-extracted Markdown or text chunks. A raw SERP response includes navigation menus, footer text, ads, and boilerplate that consume context window space without contributing to the answer. LLM-optimized APIs filter this out before the response leaves their servers.
Pipeline complexity. Multi-step vs. single-call. According to Built In's analysis, LLM-optimized search APIs handle data cleaning, noise removal, and structuring automatically, steps that SERP API users must implement themselves.
SERP API vs. LLM Search API: Side-by-Side
Teams running Sona AI Visibility audits to understand how AI engines read and cite their content will recognize the same logic at work here. AI engines and LLM search APIs reward content that is clean, structured, and semantically coherent. Sites that score well on AI visibility checks tend to surface more reliably in LLM-optimized search results, because the signals that make content crawlable by GPTBot are the same signals that make it extractable by search APIs.
Frequently Asked Questions
What is the best LLM search API for RAG pipelines?
Tavily is the strongest LLM search API for RAG pipelines as of April 2026. It performs search, scraping, filtering, and content extraction in a single API call, returning clean, relevance-ranked text ready for LLM consumption without additional preprocessing. Its native LangChain integration (`TavilySearchResults`) makes it the fastest path from zero to a working RAG pipeline.
Is there a free LLM search API I can use to prototype AI agents?
Yes. Tavily offers a free tier covering approximately 1,000 searches per month. Google Programmable Search Engine provides 100 free queries per day. Brave Search API has a free tier with access to its LLM Context endpoint. For semantic search evaluation, Exa provides trial credits. None of these require a credit card to start.
How do I integrate a search API with LangChain in Python?
LangChain provides an official tool wrapper for Tavily (`TavilySearchResults`) and community wrappers for Brave and SerpAPI. Install the provider's SDK, set your API key as an environment variable, initialize the tool with your preferred parameters (max results, search depth), and pass it to your LangChain agent's tools list. Most integrations require fewer than 10 lines of setup code. The freeCodeCamp Tavily guide covers this end-to-end with working examples.
What is the difference between Tavily and SerpAPI for LLM use cases?
Tavily is purpose-built for LLMs. It returns pre-extracted, AI-ranked content in a single call with no additional scraping or parsing required. SerpAPI returns raw Google SERP data (titles, URLs, snippets) that requires a scraper, HTML parser, and chunker before an LLM can use it effectively. For RAG pipelines and AI agents, Tavily reduces pipeline complexity by four to five steps. SerpAPI remains useful when you need raw Google SERP data for non-LLM purposes or when broad Google coverage outweighs the processing overhead.
How does real-time web search prevent LLM hallucinations?
Real-time search APIs ground LLM responses in live, verifiable web content retrieved at inference time. Instead of relying on static training data with a fixed knowledge cutoff, the LLM receives current source material as context before generating its response. The mechanism is not foolproof (the model can still misread retrieved content), but grounding in live sources removes the class of errors caused by outdated training data.
What is the Brave LLM Context API and how does it work?
The Brave LLM Context API is a search endpoint built for AI agent and RAG use cases. It accepts queries up to 400 characters (50 words maximum), returns relevance-scored content chunks in Markdown format, supports freshness filtering by date range, and is optimized for LLMs with 32k or larger context windows. It replaces the need to scrape and parse Brave search results manually, delivering structured, AI-ready content in a single call.
Can I use a Google search API with an LLM?
Yes. Google Programmable Search Engine and third-party wrappers like SerpAPI provide access to Google search results via API. Both return raw SERP data requiring additional processing (scraping, parsing, chunking) before it is LLM-ready. Google PSE is a strong choice when breadth of web coverage is the priority and your pipeline already handles the post-processing steps.
What are the main limitations of LLM search APIs?
Four limitations matter most in production. First, per-query costs accumulate at scale: at $0.01 per search, a pipeline running 100,000 queries per month costs $1,000 in search API fees alone. Second, rate limits (some APIs cap at 20 calls per second) create bottlenecks in high-volume agent workflows. Third, each call adds approximately one second of latency, which compounds in multi-step agent chains. Fourth, every query sent to an external API leaves your infrastructure, raising privacy considerations for pipelines handling sensitive B2B data.
Last updated: April 2026



